# 교차 검증
- 머신러닝 모델의 성능을 평가하는 기법 중 하나
- 데이터를 여러 번 반복해서 나누어 모델을 학습하고 평가하는 방법
- 교차 검증은 일반화 성능을 더 정확하게 추정하고, 모델이 특정 데이터에 과적합(overfitting)되지 않도록 도와준다.
- 과적합: 모델이 학습 데이터에만 과도하게 최적화되어 실제 예측을 다른 데이터로 수행할 경우 예측 성능이 과도하게 떨어지는 것
# K 폴드 교차 검증
- 가장 보편적으로 사용되는 교차 검증 기법
- K개의 데이터 폴드 세트를 만들어 K번만큼 각 폴드 세트에 학습과 검증 평가를 반복적으로 수행하는 방법
# KFold 클래스를 이용하여 붓꽃 데이터 세트를 교차 검증하고 예측 정확도 알아보기
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
from sklearn.model_selection import KFold
import numpy as np
iris = load_iris()
features = iris.data # 독립변수
label = iris.target # 종속변수
dt_clf = DecisionTreeClassifier(random_state=156)
# 5개의 폴드 세트로 분리하는 KFold 객체와 폴드 세트별 정확도를 담을 리스트 객체 생성
kfold = KFold(n_splits=5)
cv_accuracy = []
print('붓꽃 데이터 세트 크기:',features.shape[0])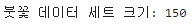
n_iter = 0
# KFold 객체의 split( ) 호출하면 폴드 별 학습용, 검증용 테스트의 로우 인덱스를 array로 반환
for train_index, test_index in kfold.split(features):
# kfold.split( )으로 반환된 인덱스를 이용하여 학습용, 검증용 테스트 데이터 추출
X_train, X_test = features[train_index], features[test_index]
y_train, y_test = label[train_index], label[test_index]
#학습 및 예측
dt_clf.fit(X_train , y_train)
pred = dt_clf.predict(X_test)
n_iter += 1
# 반복 시 마다 정확도 측정
accuracy = np.round(accuracy_score(y_test,pred), 4)
train_size = X_train.shape[0]
test_size = X_test.shape[0]
print('\n#{0} 교차 검증 정확도 :{1}, 학습 데이터 크기: {2}, 검증 데이터 크기: {3}'
.format(n_iter, accuracy, train_size, test_size))
print('#{0} 검증 세트 인덱스:{1}'.format(n_iter,test_index))
cv_accuracy.append(accuracy)
# 개별 iteration별 정확도를 합하여 평균 정확도 계산
print('\n## 평균 검증 정확도:', np.mean(cv_accuracy))
728x90
'Machine Learning' 카테고리의 다른 글
| [ML] 하이퍼 파라미터 튜닝 (0) | 2024.03.05 |
|---|---|
| [sklearn] Stratified K 폴드 (2) | 2024.03.05 |
| [sklearn] Model Selection (2) | 2024.03.05 |
| [sklearn] Estimator (0) | 2024.03.05 |
| [ML] 분류 성능 평가 지표 (0) | 2024.02.20 |