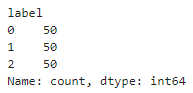
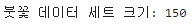# 개념막대 차트: 데이터를 막대로 나타내는 차트로, 값을 비교할 때 주로 사용한다. 가로 또는 세로 방향으로 늘어뜨린 막대들이 데이터를 시각적으로 표현하며, 막대의 길이는 데이터 값의 크기에 비례한다.막대 차트의 특징과 장점막대의 길이나 높이로 데이터 값을 비교할 수 있어, 상대적인 크기 차이를 빠르게 파악할 수 있다.간단한 구조로 데이터를 쉽게 이해할 수 있도록 도와주며, 축과 레이블을 통해 데이터를 명확하게 표현할 수 있다.데이터의 상승과 하락을 시각적으로 보여주고, 데이터의 패턴이나 추세를 시각화하는 데 유용하다.막대 차트는 데이터의 분포를 직관적으로 파악할 수 있다. 또한, 여러 개의 막대를 나란히 놓아 비교 분석을 할 수 있으며, 시각적 요소를 추가하여 정보를 더욱 명확하게 전달할 수 있다. ..